
最近在做项目的时候,发现数据统计请求接口很慢,因此考虑将多个任务并行跑,这里主要采用的ForkJoinPool来实现,这是因为这个线程池可以配合parallelStream()方法来做自定义线程池,做任务线程的隔离。
get()
这个方法,在文档中有以下描述:

这个方法在执行的时候,如果程序异常、任务被取消、被打断都会抛出异常,因此不同的异常需要我们自行的处理。
例如一下程序:
package com.ai.bss.res.console.util;
import org.junit.Test;
import java.util.Arrays;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
public class ForkJoinPoolTest {
@Test
public void testParallelStream() throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool(10);
forkJoinPool.submit(() -> Arrays.stream(new int[]{1, 2, 3, 4, 5, 6, 7})
.parallel()
.forEach(e -> {
System.out.println(Thread.currentThread().getName() + ":" + (e + 5));
})).get();
}
}
则会有以下输出:

join()

这个方法与get()不同的是,这个方法不会产生异常信息,对于异常的处理,可以通过ExceptionHandler去做处理。

fork()
这个方法是比较有意思,我最开始认为,当我们fork()的时候,能够帮助我们快速的执行任务,但是通过读取方法文档:
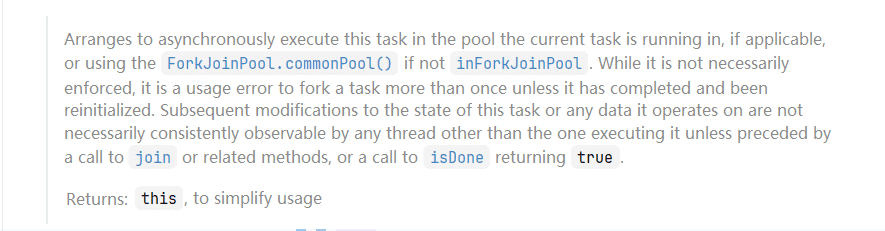
大致意思是:当我们使用ForkJoinPool执行任务的时候,可以通过fork方法让任务通过CommonPool通用的线程池来并行的执行任务。
但是,这可能会导致任务同时被执行多次,合适因为,通过CommonPool执行任务的时候,可能对应的任务还没有执行完成,但是CommonPool执行并不关心,还是会执行的。

如果大家有什么更好的想法,可以在评论区交流
